TL;DR: We enable text-based image editing using 3-4 step diffusion models
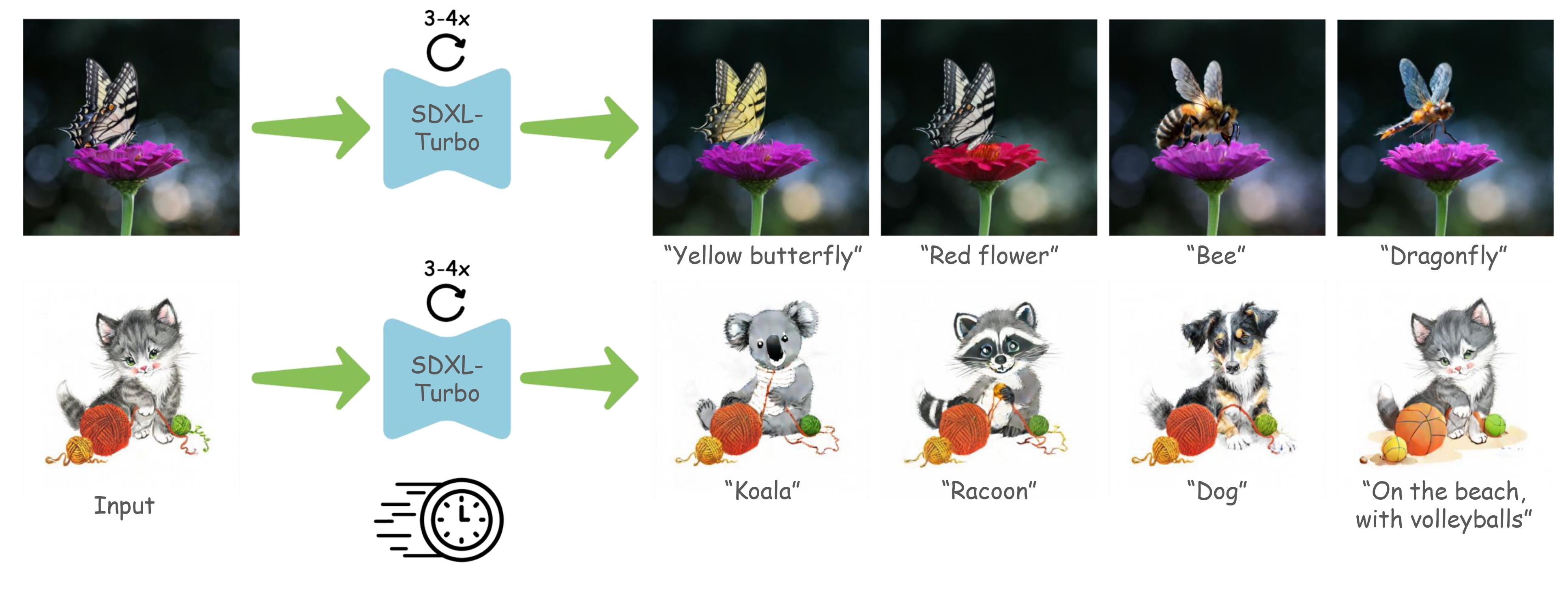
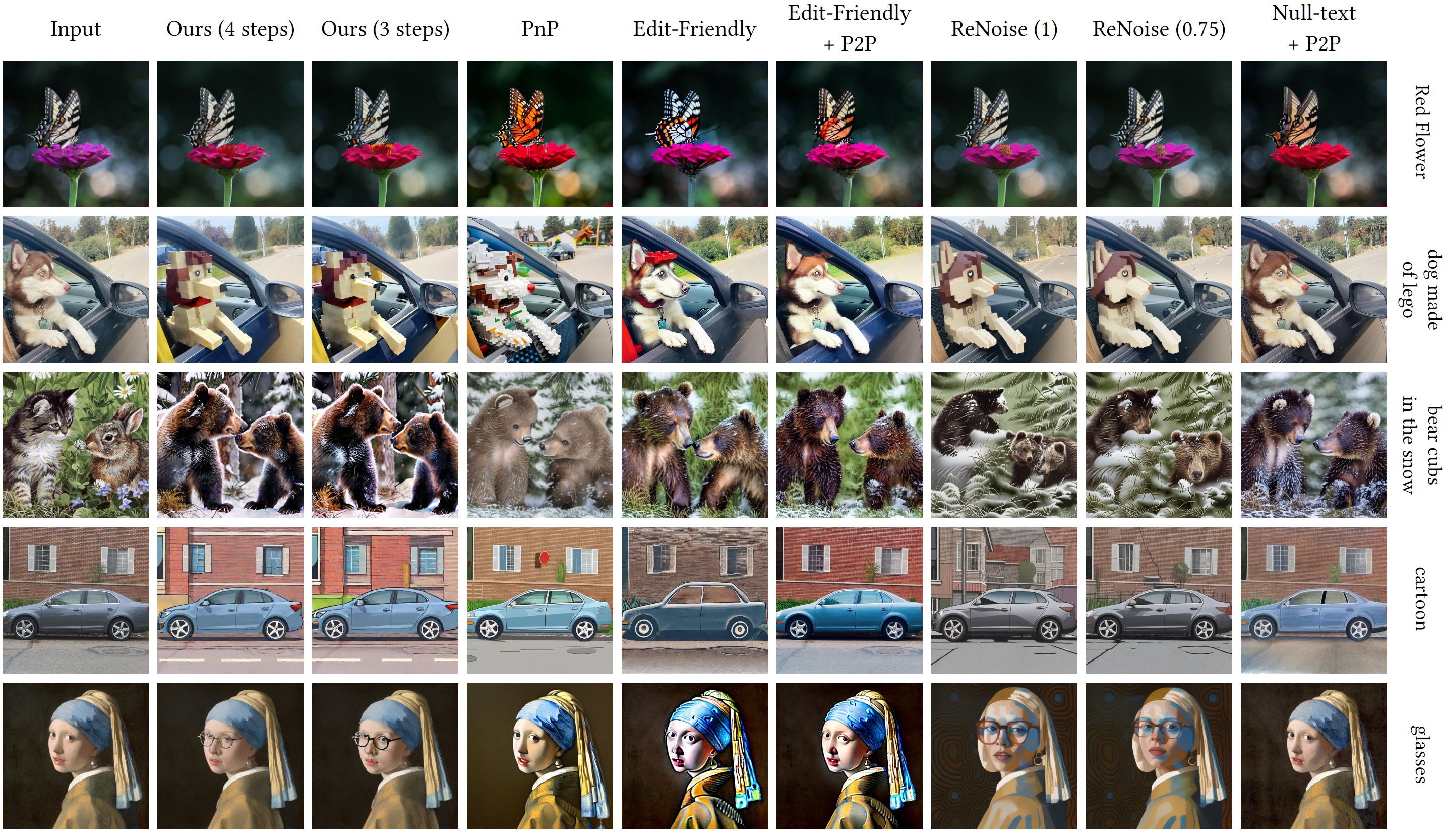
Diffusion models have opened the path to a wide range of text-based image editing frameworks. However, these typically build on the multi-step nature of the diffusion backwards process, and adapting them to distilled, fast- sampling methods has proven surprisingly challenging. Here, we focus on a popular line of text-based editing frameworks - the “edit-friendly” DDPM-noise inversion approach. We analyze its application to fast sampling methods and categorize its failures into two classes: the appearance of visual artifacts, and insufficient editing strength. We trace the artifacts to mismatched noise statistics between inverted noises and the expected noise schedule, and suggest a shifted noise schedule which corrects for this offset. To increase editing strength, we propose a pseudo-guidance approach that efficiently increases the magnitude of edits without introducing new artifacts. All in all, our method enables text-based image editing with as few as three diffusion steps, while providing novel insights into the mechanisms behind popular text-based editing approaches.
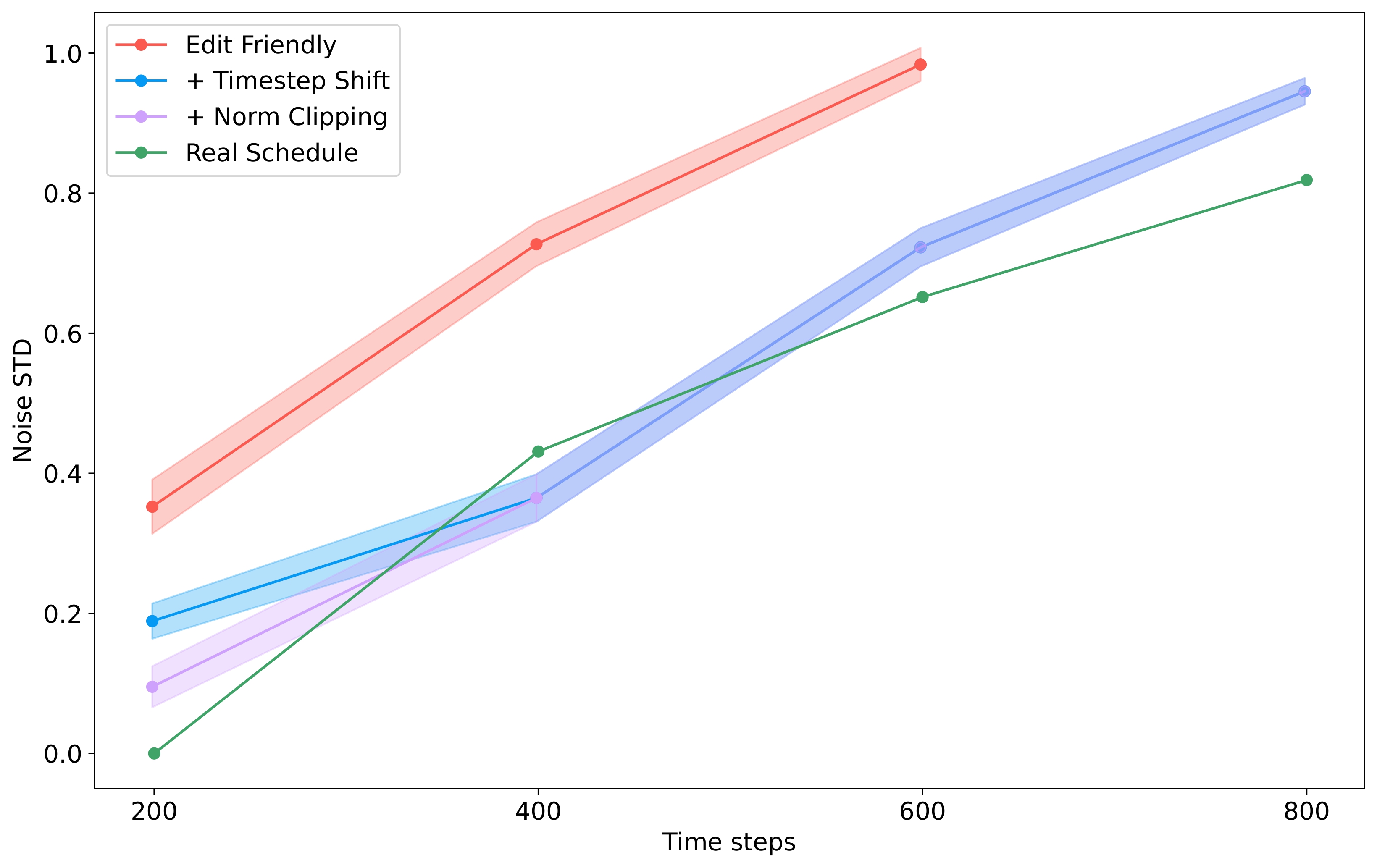

Our investigation into the Edit-Friendly DDPM proccess reveals that it shares similar form to the corrections employed by Delta Denoising Score. Surprisingly, we prove that under an appropriate choice of learning rates and time-step sampling, the two methods are functionally equivalent and create the exact same results. This finding can also be extended to the recent Posterior Distillation Sampling (PDS) method, if applied to image editing.



If you find our work useful, please cite our paper:
@misc{deutch2024turboedittextbasedimageediting,
title={TurboEdit: Text-Based Image Editing Using Few-Step Diffusion Models},
author={Gilad Deutch and Rinon Gal and Daniel Garibi and Or Patashnik and Daniel Cohen-Or},
year={2024},
eprint={2408.00735},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2408.00735},
}